本文系论文 Online Multi-target Tracking using Recurrent Neural Networks (arXiv 2016)的阅读笔记。
RNN-Tracking 的主要贡献并不在于表观模型(appearance models),而在于运动模型(motion models)和目标指认(target assignment)。文章实验是在 MOT(Multiple Object Tracking) 数据集上做的,达到了 300+ fps 的速度。注意 MOT 里的跟踪目标仅有行人。RNN-Tracking 用基本的 DPM (Deformable Part Models) 在每帧中检测行人的位置,再根据历史记忆判断它们属于哪个目标,同时判断有无行人进入或离开视野。后面两件事情是通过一个 end-to-end 的 RNN+LSTM 网络模型来实现。
RNN-Tracking 的主要流程如下图所示:
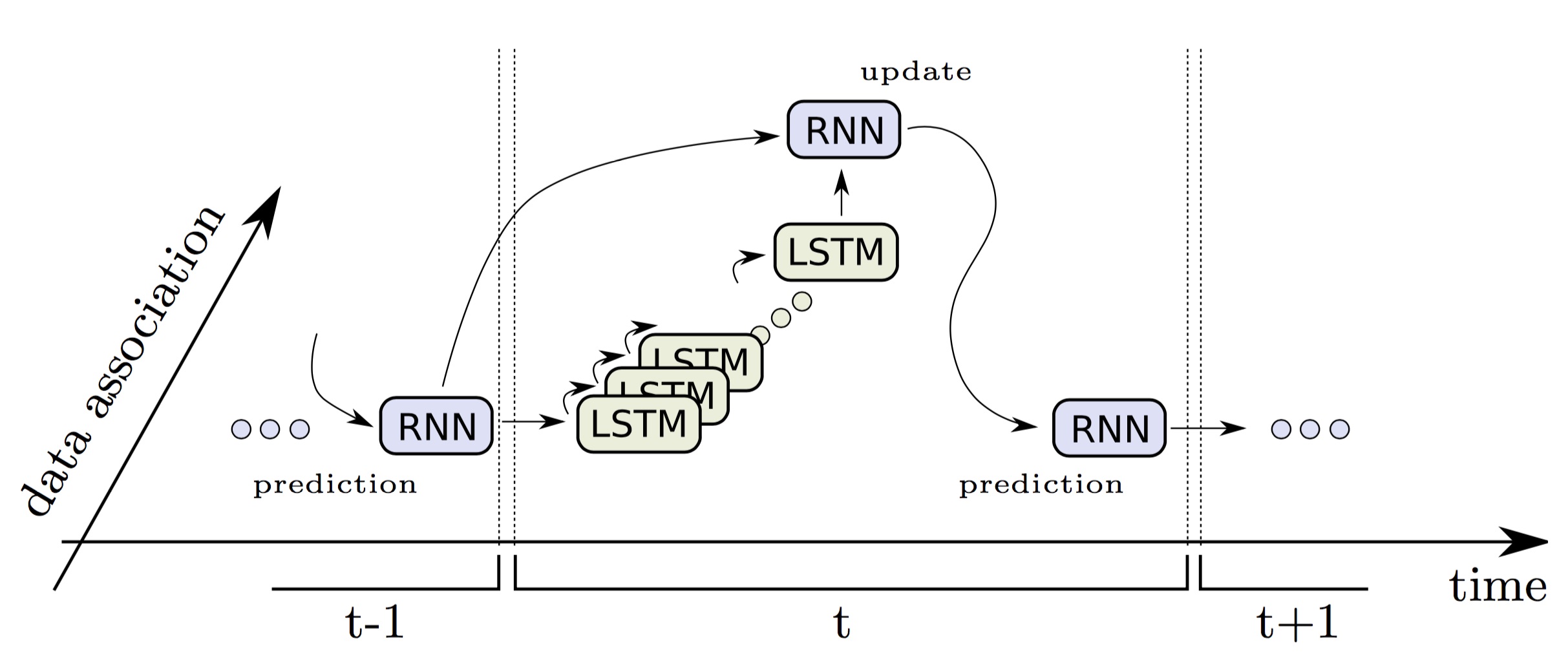
所以每帧里的 tracking 过程包括:
- 预测(predict):根据上帧目标位置 $x_t$ 估计下帧位置 $x^*_{t+1}$ (RNN)
- 目标检测(detect):文中(包括上图中)并未提及具体用什么方法检测行人,邮件询问作者,告知是基于 DPM 检测行人 (DPM)
- 目标指认(assignment):根据特征(文中是以 $M$ 个检测结果与 $N$ 个预测位置的距离矩阵 $C$ 作为特征,你可以加入表观特征)估计指认概率矩阵(assignment probability matrix)$A \in [0,1]^{N \times (M+1)}$ (LSTM)
- 更新(update):根据指认概率更新预测的目标位置,并判断目标的 entry/exit (LSTM)
事实上,由于梯度衰减的原因,RNN 只能学习短期的依赖关系。而运动模型需要学习的正是短期的依赖关系 —— 根据之前较短一段时间里的位置、速度、加速度来预测当前的位置和尺度。RNN 的隐层节点隐式地学习了位置的变化规律。
但是,指认目标(或数据关联,将当前检测到的行人与在跟踪的不同目标关联起来)则需要模型记住不同目标在更长时间里的表观特征,这样在短期遮挡、形变或光照变化时不至于发生漂移。所以作者使用 LSTM 来建模输入特征输出指派概率矩阵的过程。尽管作者只是提出一个框架,因为文中使用的特征并不包含表观信息,而仅仅是目标(targets)到检测结果(measurements)之间的距离矩阵。
以下是其 RNN 和 LSTM 的具体结构:
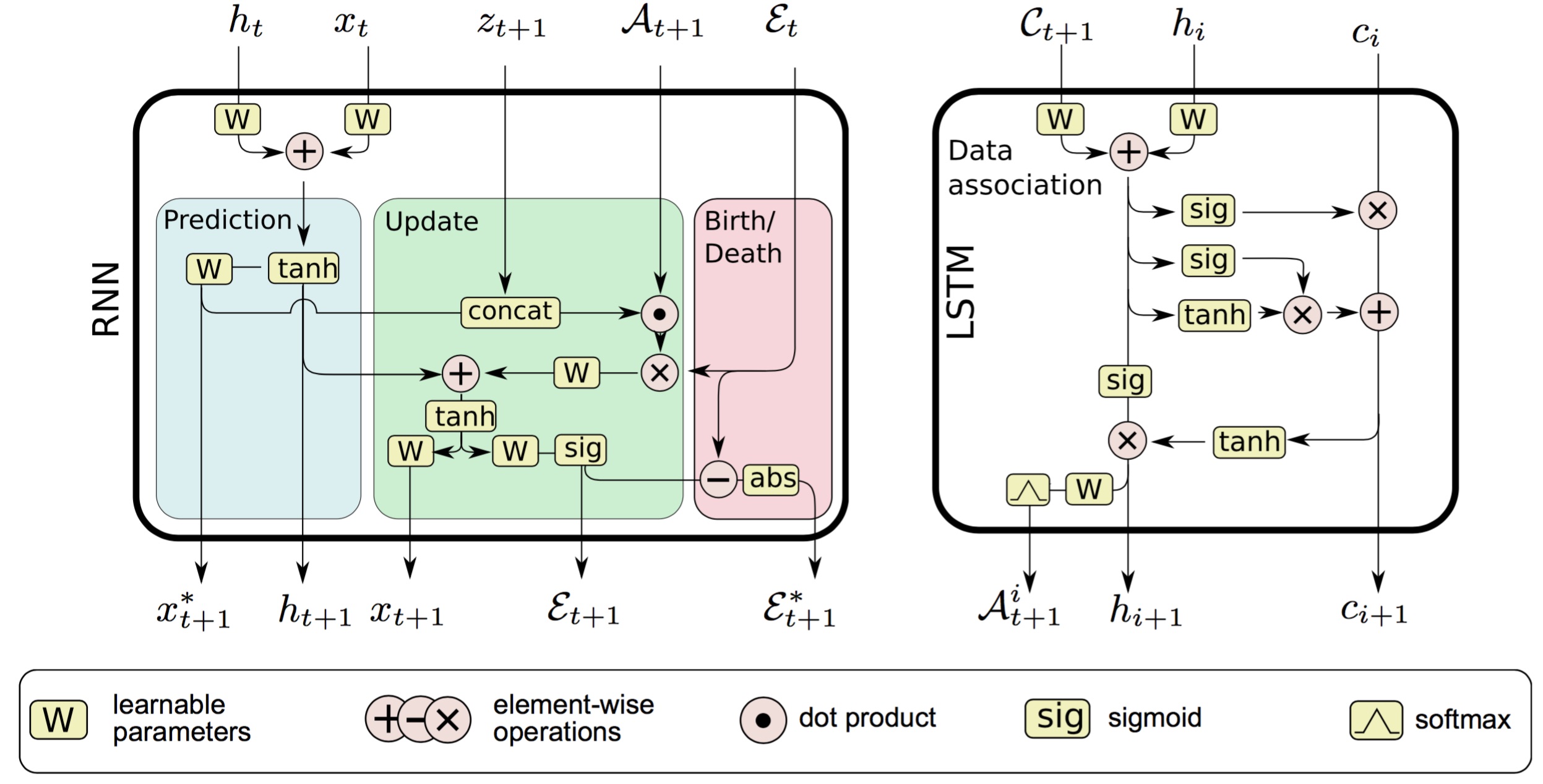
其中 RNN 的损失函数是 prediction 与 update 的 MSE (mean squared error) 加上进/出概率的估计偏差,LSTM 的损失函数是估计指认概率矩阵与真实指认矩阵的 NLL (negative log-likelihood)。
RNN-Tracking 中使用 short-term 的 RNN 来建模运动模型,并使用 long-term 的 LSTM 来建模表观模型,这是个十分值得借鉴的思想。